
GSAI IIR & GSAI-ML团队 投稿
量子位 | 公众号 QbitAI
传统的搜索Agent有个问题:想完了才去搜,搜的时候干等着,等完了再接着想。
就像你去餐厅点菜,非要把菜单研究透了才叫服务员,服务员去下单的时候你又呆坐着发愣,菜上了你才开始想下一道点什么。
正常人不是这样吃饭的。你会一边看菜单一边叫服务员,服务员去下单的时候你继续研究下一道菜点什么。

中国人民大学团队在论文DLLM-Searcher中,第一次让扩散大语言模型(dLLM)学会了这种“一心二用”的本事。
先说清楚问题出在哪
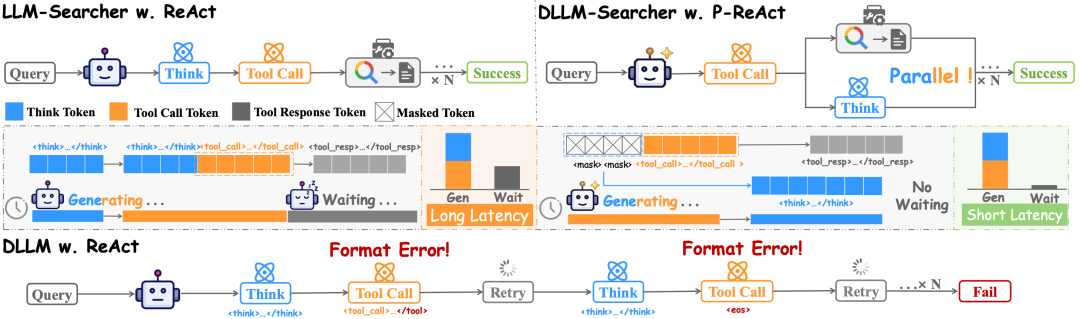
目前主流的搜索Agent,不管是Search-R1还是R1Searcher,用的都是ReAct框架。这个框架的执行流程是严格串行的:
想→调工具→等结果→再想→再调工具→再等……
每一轮里,“想”和“调工具”是模型一个token一个token从左到右吐出来的,等搜索引擎返回结果的时候模型完全闲着。多轮下来,延迟叠延迟,用户体验直接拉胯。
团队算了笔账:在多跳问答任务里,这种串行等待吃掉了大量的端到端时间。
那能不能让模型在等搜索结果的时候,继续想下一步?
自回归模型做不到。因为它的注意力是因果的,必须“先想清楚才能说出来”,你让它先输出工具调用再输出思考,性能会大幅下降:实验里Qwen3系列模型换了顺序后准确率明显掉点。
但扩散语言模型天生就能做到。
扩散模型凭什么能“一心二用”?
扩散大语言模型(dLLM)和传统自回归模型最大的区别在于:它不是从左到右一个个吐token的,而是所有位置同时“去噪”,逐步从一团马赛克里浮现出完整文本。
这意味着两件事:
第一,生成顺序是自由的。模型可以先把最重要的部分解码出来,其他部分慢慢补。
第二,模型“还没说出来”的时候就已经“想到了”。因为块内是双向注意力,即使思考部分还是一堆[MASK],工具调用部分在解码时依然能利用到潜在的推理信息。
用论文里引用的一句话说:扩散模型在解码之前就已经知道答案了。
但理论归理论。实际一试,现有的dLLM直接拿来当搜索Agent,全崩了。
原始dLLM有多拉胯?
团队拿当前最强的块扩散语言模型SDAR,直接套ReAct框架跑HotpotQA的500条测试题。
结果是:成功率0%。500题全在第一轮就因为格式错误挂掉了。
具体的崩法也很有“创意”——31.2%的情况下模型直接输出结束符,什么都不说;28.4%的情况想了半天但忘了调工具;17.8%的情况连标签都写不完整;还有7%写出了不合法的工具调用格式。
一句话总结:dLLM虽然有并行生成的潜力,但它既不会推理,也不会调工具。
两阶段训练:先教规矩,再教本事
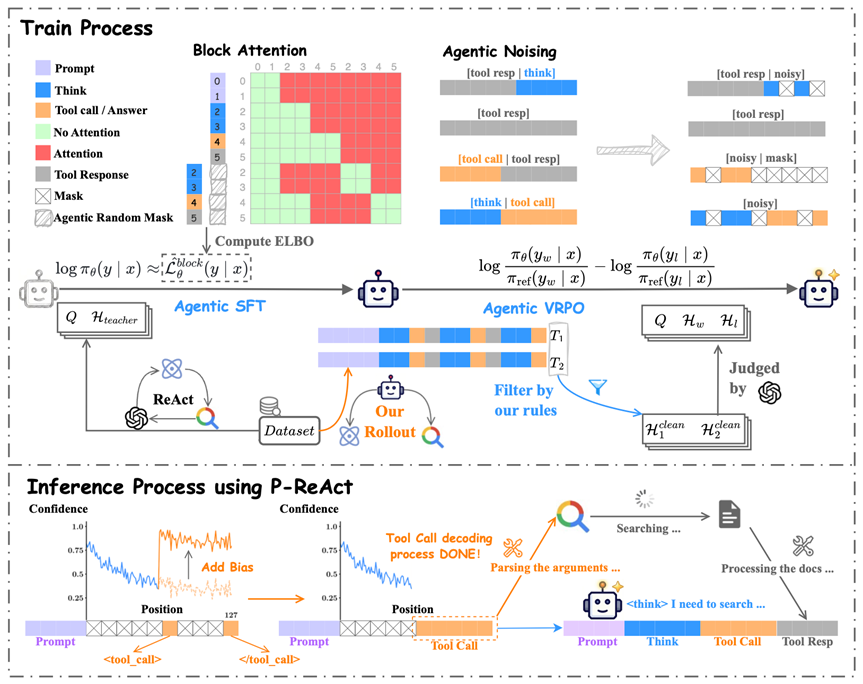
为了把dLLM从“啥也不会”调教成合格的搜索Agent,团队设计了一套两阶段后训练流程。
第一阶段:Agentic SFT(监督微调)。让强模型(豆包Seed-1.8)先跑一遍搜索任务生成标准轨迹,筛掉答错的、格式不对的、推理不完整的,剩下3977条高质量轨迹喂给dLLM。
但这里有个技术难点:搜索轨迹里既有模型自己生成的“思考”和“工具调用”,也有搜索引擎返回的“工具响应”。这里只需要模型学前者,不需要它去记忆后者。
而且dLLM块内是双向注意力,如果不做处理,模型在训练时会偷看到同一个块里还没生成的搜索结果——这就像考试的时候答案就摊在旁边,训练时看得到,推理时看不到,直接导致训练和推理的不匹配。
团队为此专门设计了Agentic Noising:只对“思考”和“工具调用”部分加噪,搜索结果部分要么保留原样(当它在思考之前出现时,作为上下文),要么直接全部遮掉(当它和生成部分在同一个块里时,防止信息泄露)。配套的Agentic ELBO损失函数也只在需要学习的位置上计算,搜索结果位置完全不参与梯度回传。
第二阶段:Agentic VRPO(方差缩减的偏好优化)。用第一阶段训好的模型自己跑两遍,挑出“一对答对一对答错”的轨迹对,通过偏好学习进一步拉开正确和错误推理路径的差距。筛出2237组有效训练对,效果在所有数据集上都再涨了3个百分点以上。
P-ReAct:让工具调用插队
训练解决了“会不会”的问题,但“快不快”还需要一招。
这就是论文提出的P-ReAct(Parallel-Reasoning and Acting):一个不需要额外训练的推理加速方案。
核心思路极其简洁:
第一步,预填充边界标记。在每轮生成开始时,不是给模型一整块[MASK],而是提前在后半部分放好和两个锚点。这等于告诉模型:“这两个标记之间,是你要填工具调用的地方。”
第二步,给工具调用区域的置信度加偏置。扩散模型每一步会给所有位置的候选token打一个置信分,然后优先解码置信分最高的位置。P-ReAct在工具调用区域的置信分上统一加一个正偏置(α=0.5),人为拉高这些位置的优先级。
效果是:模型几乎100%会先把工具调用解码完毕,立刻发送给搜索引擎;然后在等搜索结果返回的这段时间里,继续填充思考部分。
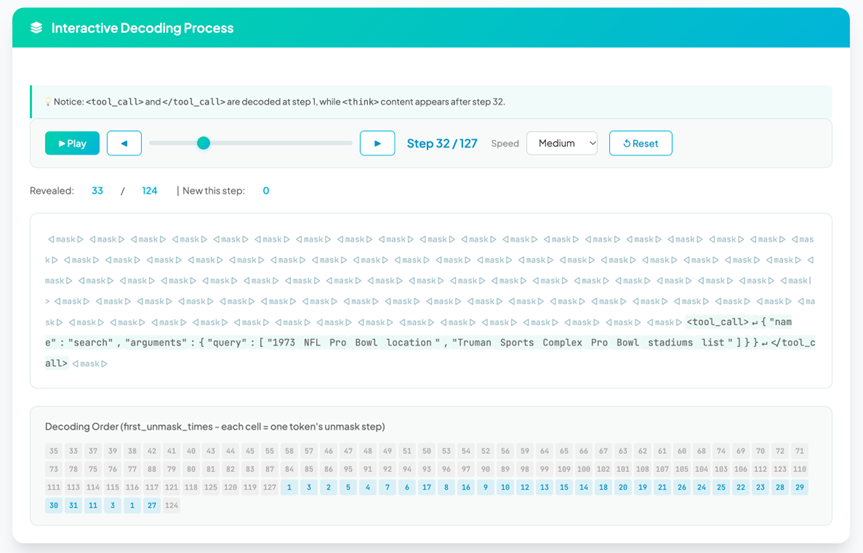
论文里展示了一个真实案例的解码顺序:在第32步时,工具调用区域已经全部解码完成,而思考区域还全是[MASK]。直到最后阶段思考部分才被补全。模型真的实现了“先动手、后想明白”。
效果怎么样?
在HotpotQA、2WikiMultiHopQA、Bamboogle、Musique四个多跳问答基准上:
DLLM-Searcher的平均准确率达到57.0(ACC_R)/ 56.6(ACC_L),全面超越所有传统RAG方法,与自回归搜索Agent R1Searcher打成平手甚至小幅领先。
而且这个成绩是在P-ReAct加速模式下跑出来的。P-ReAct带来了14.77%到22.08%的端到端推理加速,性能几乎没有损失。
作为对比,让自回归模型(Qwen3系列)也尝试“先输出工具调用再输出思考”,结果准确率显著下降。这说明“先行动后思考”这件事,是扩散模型独有的结构性优势,自回归模型学不来。
更值得注意的是,DLLM-Searcher只用了不到8000条训练数据,就在域外数据集Bamboogle上也取得了68.8的高分,泛化能力相当强。
这意味着什么?
一直以来,扩散语言模型被认为是自回归模型的“潜力股替代品”,但在推理和Agent场景下一直表现拉胯。DLLM-Searcher第一次证明:经过针对性训练,dLLM不仅能追上自回归模型的推理能力,还能利用自身的并行生成优势做到自回归模型做不到的事,实现了真正的在等待时保持思考。
这给搜索Agent的效率优化打开了一条全新的路。
论文引用了Ray Kurzweil的一句话:“我们实际上在意识到自己做出决定之前就已经开始行动了。”扩散模型的解码机制,还真有点这个意思。
论文标题:
DLLM-Searcher: Adapting Diffusion Large Language Models for Search Agents
第一作者:
赵嘉浩、徐少轩(中国人民大学),孙忠祥(中国人民大学,项目负责人)
通讯作者:
徐君(中国人民大学)
arxiv:
https://arxiv.org/abs/2602.07035
github:
https://github.com/bubble65/DLLM-Searcher
项目主页:
https://bubble65.github.io/dllm-searcher-pub/
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
我们正在招聘一名眼疾手快、关注AI的学术编辑实习生 🎓
感兴趣的小伙伴欢迎关注 👉 了解详情

🌟 点亮星标 🌟
科技前沿进展每日见
富腾优配提示:文章来自网络,不代表本站观点。
相关文章



沪深京行情 实时轮播
热点资讯
